

 Next-Gen Supply Chain – From Automation to Full Autonomy">
Next-Gen Supply Chain – From Automation to Full Autonomy">

Implement a centralized autonomous control plane today to orchestrate robotics, sensing, and software, integrating data streams from ERP and WMS. In your 센터, coordinate inventory, 주문, and routing with real-time data, while keeping a lean governance model that assigns clear ownership to each function.
From a 기능적인 perspective, deployment reduces human error and raises satisfaction for operators and customers. The 현재 state in reality shows autonomous systems handle roughly 40–60% of picking tasks in mid-size warehouses, with potential to reach the entire cycle in larger networks as sensing, edge compute, and control planes mature.
While automation defines routines, autonomy requires clear governance and scalable architecture. Functions such as order orchestration, inventory control, and carrier coordination become reliable when data is integrated across suppliers, carriers, and customers. The integrating layer bridges planning, execution, and analytics, turning fragmented data into actionable insight.
Recommendation: design an iterative rollout with a two-tier approach – pilot in a single 센터, then expand to adjacent facilities. Measure cycle time, fill rate, and satisfaction scores from operators. Use real-time dashboards to surface bottlenecks and adjust the control plane. Structure incentives for teams to adopt autonomous workflows and provide on-site training to preserve functional literacy across the workforce.
Feasibility and practical pathway to autonomous operations
Start with a 12–18 month cloud-based pilot that pairs automated execution with human-in-the-loop oversight to prove value and establish a scalable foundation for autonomous operations. Bold leadership must embrace reality and move early to set governance, standards, and risk controls.
Feasibility rests on four pillars: data readiness, technology maturity, governance, and risk management. Each stage keeps humans in the loop where appropriate and progressively increases automation density.
Where data quality and process stability meet thresholds, autonomy scales with confidence. The program moves in a data-driven manner, and teams have access to a management layer that can adapt as advances occur. It involves continuous auditing and capability reviews.
- Stage 1 – Early data readiness and standardization: consolidate ERP, WMS, and TMS feeds into a cloud-based data fabric; implement standardized data models with accuracy targets near 98% and latency under 2 minutes for core metrics; establish a single source of truth and role-based access.
- Stage 2 – Hyperautomation in controlled domains: apply artificial intelligence and automation to two to three use cases (for example demand forecasting, replenishment, and dock scheduling) with automated decisions covering up to 80% of routine tasks and human review for exceptions.
- Stage 3 – Autonomous operations in limited scope: enable autonomous decisioning and execution for selected workflows (inventory placement, carrier selection) with full telemetry and fail-safes; track cycle-time reductions of 25–40% and order accuracy rising to 95–99%.
- Stage 4 – Scale to network-wide autonomy: standardize management practices, APIs, and vendor interfaces; expand cloud-based agents across regions and onboard legacy systems; enforce security and compliance while extending autonomy to additional processes.
Implementation combines quick wins with longer-term automation integration. In the first half-year, target improvements in data quality and visibility; by months 6–12, extend automation to more facilities; by month 12–18, replicate the autonomous operating model in core routes and warehouses with cloud-based dashboards and standard interfaces.
Key capabilities to enable moving toward fully autonomous operations include: cloud-based data fabric, real-time telemetry, artificial intelligence models for forecasting and routing, policy-driven decision automation, and governance that enforces safety and reliability. The approach involves modular automation, explicit risk controls, and staged validation at each stage.
Metrics and outcomes to track: cycle-time reduction 25–40%, on-time-in-full rate improvement to 97–99%, autonomous task coverage 60–80% in initial domains, asset utilization gains of 10–20%, MTTR reduction of 30–50%, and ROI in the 150–300% range over two years. Targets achieved in early waves inform expansion and scale.
In addition, plan for a managed transition where operations teams have a clear path to upskill into automation stewardship roles. Where the system proves reliable, the organization can move bold steps forward with confidence, leveraging humans and automation in a manner that is truly able to deliver sustained improvements and competitive advantage.
Define autonomy levels for inventory, order management, and logistics
Adopt a three-level autonomy ladder for inventory, order management, and logistics: manual with human-in-the-loop; autonomous with guardrails; and fully autonomous operations when criteria and risk controls are in place.
Inventory autonomy path: Level 1 (Manual) assigns those responsible to review stock counts, set basic reorder points, and approve replenishments, keeping little automation in play and reducing errors. Level 2 (Autonomous with guardrails) lets the system place replenishments using moving demand signals, real-time stock levels, and supplier lead times, with limits defined by chief policies; it can transfer product across warehouses to balance demand, measured by metrics such as fill rate and stock-out rate. Level 3 (Fully autonomous) delivers end-to-end control with dynamic safety stock and cross-site balancing, integrating supplier networks and internal stores while exceptions route to leaders for bold decisions and feedback loops tighten the path toward optimal performance.
Order management path: Level 1 (Manual) has staff route orders, confirm backorders, and handle exceptions; Level 2 (Autonomous) includes auto-routing by service levels, automatic cancellation or resubmission of incomplete orders, and self-healing of order queues. Level 3 (Fully autonomous) provides end-to-end orchestration, splitting and reallocating orders across channels, automatic customer updates, and autonomous discrepancy handling. Track progress with metrics like order cycle time, on-time delivery, and the rate of orders processed without human intervention.
Logistics path: Level 1 (Manual) covers dispatch and carrier selection by staff; Level 2 (Autonomous) adds route optimization, carrier negotiation, automated shipment tracking, and proactive delay alerts; Level 3 (Fully autonomous) enables end-to-end transport execution with dynamic re-routing, automated invoicing, and linkage to external partners. Moving toward fully autonomous logistics requires integrating sophisticated computing, real-time visibility, and bold feedback to leaders for continuous improvement.
Establish a data fabric: data quality rules, real-time visibility, and partner data exchange
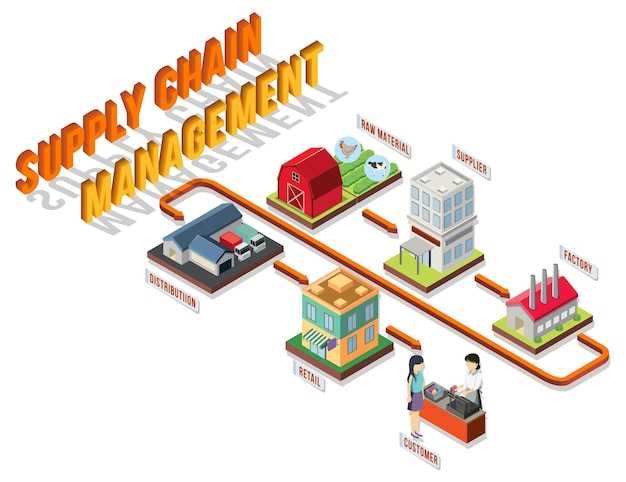
Implement a data fabric now by defining data quality rules, enabling real-time visibility, and enabling partner data exchange to transform operations across the value chain. Use a standard data model that is shared across ecosystems, ensuring customer data is accurate and timely. This setup helps teams become informed and ready to act. Use only trusted sources to drive velocity.
Establish a data quality rulebook that covers accuracy, timeliness, completeness, and lineage. Automating checks run in a sequence and are enforced by data stewards. They should be updated based on recent feedback from users and partners, and be able to stop bad data before it propagates. The program involves governance, automation, and continuous improvement, and the aim is to achieve data integrity with minimal manual labor.
Real-time visibility: Provide a unified view of data quality, gaps, and freshness across systems. Use streaming, event-driven pipelines, and change data capture to reduce lag, making data available when decisions matter. They remain fully capable of supporting intelligent decisions, with dashboards that facilitate proactive actions and informed responses.
Partner data exchange: Establish standard data contracts with suppliers and customers, and define API schemas to enable seamless data sharing with them. Build digitisation-friendly gateways that connect them into the fabric without friction, and ensure data exchanged with them maintains quality. Use the exchange to facilitate collaboration and accelerate value across ecosystems.
Stage-gate governance: Use a staged rollout with a pilot set of partners, then scale to leading ecosystems. This approach makes data quality a shared responsibility and a visible asset. Before broad deployment, verify that data quality rules hold for edge cases and that feedback loops are closed. At this stage, governance is transparent and decisions are traceable.
Measurable outcomes and targets: Latency for core data should stay under a few seconds, data accuracy above 99.5%, and manual data-handling labor reduced by 15–25% within six months. The outcomes achieved include improved trust and faster decisions. Implement predictive alerts to anticipate data quality issues and trigger automated fixes before customers notice disruptions. This path aligns with digitisation goals.
Choose the right tech stack: sensors, edge computing, ML models, and integration patterns
Recommendation: adopt a standard, modular tech stack: sensors at the edge, edge computing, ML models, and clean integration patterns. Focus on data quality: standard interfaces (MQTT, OPC UA), self-calibrating sensors, and a data contract that records times, units, and quality flags. This reduces errors and speeds response. Build repetitive checks into automated functions and use digitisation to cut manual work. There, edge compute handles time-critical decisions, increasing resilience, greater stability, and reduced downtime. Your system becomes more capable, and humans can focus on exception handling rather than routine monitoring.
Edge and ML model design: choose lightweight models for edge deployment–anomaly detection, predictive maintenance, demand signals, and route optimization. Keep models modular and versioned; push training pipelines to the cloud and deploy updates to edge devices. Use quantization, pruning, or distillation to fit memory constraints; aim for small footprints that run in milliseconds. This two-tier setup lets edge handle real-time decisions while the cloud handles long-horizon digitisation and trend analysis, boosting efficiency and reducing cloud traffic, enabling faster response to long orders. This approach makes your operations truly capable of adapting to changes faster, with less reliance on central systems.
Integration patterns: API-first with versioned contracts, event-driven streams, and a central message bus. Use MQTT for sensors, REST or gRPC for internal services, and OPC UA where needed. Define data contracts with timestamps, quality flags, and unit metadata; implement idempotent functions and robust retry policies. Apply backoff, circuit breakers, and observability to catch errors early. Align with suppliers and leaders to keep your stack standard and scalable; design adapters to operate outside vendor boundaries and avoid lock-in. Consider another adapter layer to connect legacy systems and ensure long-term interoperability. You must enforce security and governance across all layers, centering control at a center of coordination to sustain reliability.
Design decision-making and control loops: from automation rules to autonomous decision governance

Implement a next-gen decision framework using a sophisticated governance layer atop automation rules. This better approach helps systems respond faster, take real-time signals, and always keep feedback at the center. Using digitising data from supplier portals, manufacturing lines, and products, you implement autonomous decisions without manual intervention. The long-term role of each decision point, with functional owners, is to manage change and reduce manual labor, becoming able to focus on exceptions and optimisation.
Identify decision points across planning, execution, and replenishment. Map data inputs from sensors, ERP events, WMS notices, and external signals. Align automation with the functional role of each decision node and ensure versioned policies, traceability, and auditability. Emphasize labor-saving by digitising flows and maintaining a clear plan for continuous improvement. Establish governance thresholds that trigger escalation when risk rises or when a decision is not feasible, and involve product owners to maintain alignment with market conditions.
명확한 경계를 가진 설계 제어 루프: 자동화 루프는 결정적 규칙을 실행합니다. 피드백 루프는 결과를 측정하고 피드백을 사용하여 매개변수를 조정합니다. 강력한 자율 의사 결정 거버넌스 루프는 정책 제약 조건 및 위험 점수에 따라 조치를 검증하고 필요한 경우 사람에게 에스컬레이션합니다. 인공 지능 구성 요소는 예측 및 이상 탐지를 개선하지만 거버넌스 계층은 항상 최종 책임을 지고 이벤트에 신속하게 대응할 수 있습니다. 응답 시간이 운영에 부합하도록 보장합니다: 라인 제어는 1초 미만, 보충 계획은 몇 분 이내, 각 기능에 대한 소유자 정의. 이 설정은 더 나은 조치를 취하고 피드백을 사용하여 모델을 개선하며 시스템 및 제품 전반에 걸쳐 신호를 디지털화하는 데 도움이 됩니다.
| 루프 유형 | 역할 | 의사결정 유닛 | 데이터 입력 | 실행 가능한 | KPI 영향 |
|---|---|---|---|---|---|
| 자동화 규칙 | 작동 결정론 | 규칙 엔진 | 센서 데이터, ERP 이벤트 | Yes | 처리량 +15%, 사이클 시간 -20% |
| 피드백 제어 | 서비스 수준 유지 | 컨트롤러 | 실시간 메트릭, 백로그, 재고 | Yes | OEE +5-8%, 재고 부족 위험 -30% |
| 자율 의사 결정 거버넌스 | 감독 및 적응 | 거버넌스 모듈 | 외부 신호, 정책 제약, 위험 점수 | Yes | 자동화 커버리지 +25-40% 향상, 노동 시간 절약 |
단계별 파일럿 계획 및 위험 통제: 주요 시점, KPI 및 거버넌스 구조
수요 계획, 공급업체 소싱, 주문 처리 등 2~3개 도메인에서 교차 기능 팀 및 파일럿 운영 위원회 그룹의 주도하에 12주간 단계별 파일럿을 시작합니다. 구체적인 성공 기준을 정의하고 거버넌스 주기를 설정합니다. 주간 스탠드업, 격주 임원진 검토, 12주 차 공식적인 진행/중단 결정을 내립니다. 또 다른 목표는 데이터 품질을 조기에 검증하고 데이터 소유자를 조정하고 중앙 집중식 지표 저장소를 구축하여 깨끗한 데이터 기반을 확보하는 것입니다.
주요 단계 및 KPI: M1 주 4: 데이터 파이프라인 확인, 데이터 품질 98% 이상, 예측에 활용될 초기 신호 배포. M2 주 8: 대상 워크플로에서 반복적인 단계 40% 자동화, 수동 개입 60% 감소, 실제 값 대비 ±3% 이내의 예측 정확도 달성. M3 주 12: 주문 주기 시간 15% 단축, 재고 충족률 10% 향상, 긴급 배송 비용 5% 절감 입증. 이러한 지표는 진행 상황을 가시적으로 보여주고 추세를 예측하는 데 사용될 수 있습니다. 또한 공급업체 리드 타임 변동과 같은 또 다른 지표를 캡처합니다.
거버넌스 구조: 운영, IT, 재무 부서 임원으로 구성된 운영 위원회를 설립하여 변경 사항을 승인하고, 파일럿 보드를 통해 범위 및 예산을 승인하며, 리스크 관리자 그룹을 통해 리스크 프레임워크 및 에스컬레이션 경로를 관리합니다. 중앙 집중식 변경 로그에 의사 결정을 기록하고 RACI 매트릭스를 유지하여 팀이 누가 무엇을 승인하는지 알 수 있도록 합니다. 이는 명확한 책임 소재를 확립하고 규모 확장에 따른 마찰을 줄입니다.
위험 통제: 확률 및 영향 점수가 포함된 실질적인 위험 등록 관리, 중요 자동화에 대한 심각도 매트릭스 및 게이팅 구현, 이중 통제 및 수동 오버라이드 계획 실행, 기존 프로세스 단계적 폐지 전 2~4주 동안 병렬 실행 레인 배치, 임계값을 사용하여 신호를 모니터링하고 인텔리전스 컴퓨팅을 사용하여 이상 징후 감지. 이 접근 방식은 서비스 수준을 보호하면서도 변화에 대한 신속한 대응을 지원합니다.
진화 및 확장: 파일럿이 목표를 달성하면 추가 사이트 및 제품군으로 확장 단계를 거쳐 조직의 신뢰를 얻고 불확실성을 줄입니다. 정보 및 컴퓨팅 역량을 활용하여 수요 및 공급 조건의 변화를 지속적으로 모니터링하고, 운영 모델을 혁신하도록 학습 루프를 진화시키며, 담당자를 계속 참여시키고, 변화가 진정으로 점진적이며 여러 위치에서 복제될 수 있도록 보장합니다. 단계적 접근 방식을 통해 추적 가능성을 유지하면서 효율성과 복원력을 향상시킬 수 있습니다.